CasCades opt
主要流程
- AST作为initial search space
- 从AST的根开始 top-down优化
- 层层递归,知道最顶层的root优化结束,那么优化就结束了。 p.s 暂时看起来怎么感觉和Volcano没啥区别呢? ;)
一些概念
rule:
rule 可以表示为一个(pattern, substitute) 其中patter表示为符合某种模式的一个logical expression永远是logical expressino, substitute表示为应用了这个规则之后的新的 expression, 既可以是logical也可以是physical expression, rule 的作用就是把符合pattern的logical expression转化为substitute
其实这里就可以写成python 伪代码,来帮助理解
class Rule:
def __init__(self, pattern, substitue):
self.pattern = pattern
self.substitute = substitute
def apply_rule(logical_expression):
# 只有当某个 logical_expression符合我们的pattern时,才应用规则,也就是用substitute来替换输入的logical expression
if logical_expression.match(self.pattern)
return self.substitute
else:
return logical_expression
if __name__ == "__main__":
rule_1 = Rule(some_pattern, some_substitue)
logical_expression = rule_1.apply_rule(logical_expression)
Groups
logical equivalent的 logical expression以及由这些expression 衍生出来的 physical expression属于同一个group。
以及还有multi—expr的概念,可以把更多expression压缩成某种表示。
[AB] = A join B, B join A
Logical Operators and Query Tree && Physical Operators and Execution Plan
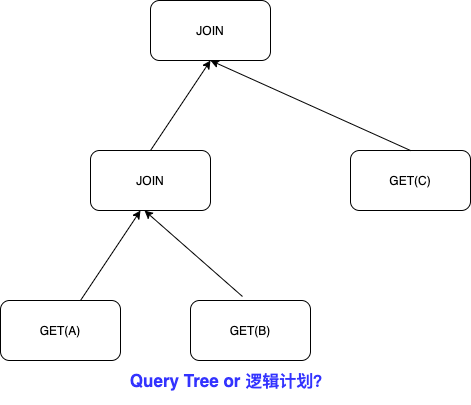
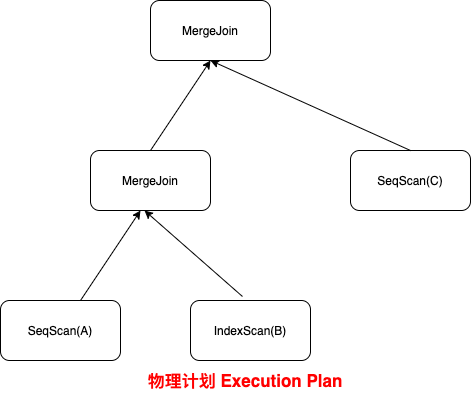
从上面两个图可以看出物理计划是通过逻辑计划通过某种具体的映射得到的。或者说逻辑计划只提供了SQL那种声明的语句,需要由物理计划来具体执行。比如逻辑计划就是JOIN(管你什么JOIN,只要是个JOIN就可以;而物理计划就得是具体的JOIN的algorithm,比如常见的就是Nested Loop, SortMerge, Hash这几种方法。
search space
Initial search space: 就是parser解析得到的AST作为Initial search space,然后 top-down根据每个node生成更多的expression,最后所有的可能的结果都出现了之后称为final search space。当然这里面还可以通过剪枝的技巧,来减小search space。
与Volcano的区别
- 用了各种Object Orient的设计,所有东西抽象的更好,比起volcano有点类似于C到 C++的感觉。
- volcano在优化之前,会先把所有的equivalent expression都生成出来, cascades之生成需要的 equivalent expression
Reference
- Yongwen Xu, Efficiency in the Columbia Database Query Optimizer (pages 1-35), in Portland State University, 1998
- G. Graefe, The Cascades Framework for Query Optimization, in IEEE Data Engineering Bulletin, 1995