Orca
Orca 是一个cascades style的优化器。
比起Cascades框架里的介绍的用的Stack来排job,虽然作者也提了一嘴, 可以用图来提高并行。 Orca比较大的改进就是使用了一个Scheduler,使得没有依赖的两个操作可以并行执行。
一些基本概念
-
Memo Memo 是一个很重要的数据结构,其实可以理解为我们刷leetcode的动态规划中的dp数组,用来保存之前计算过的结果,避免多次计算。 大概就是这个样子,初始化其实就是解析SQL,就可以表示成这个了。不过Orca为了Extensible,又加了一层DXL表示,再由DXL转换而来。

-
Transform
- Explore: Logical Expression -> Logical Expression
- Implement: Logical Expression -> Logical Expression
- enforcer: 某些操作,不存在对应的Logical Expression比如 sort, decompress
代码执行流程
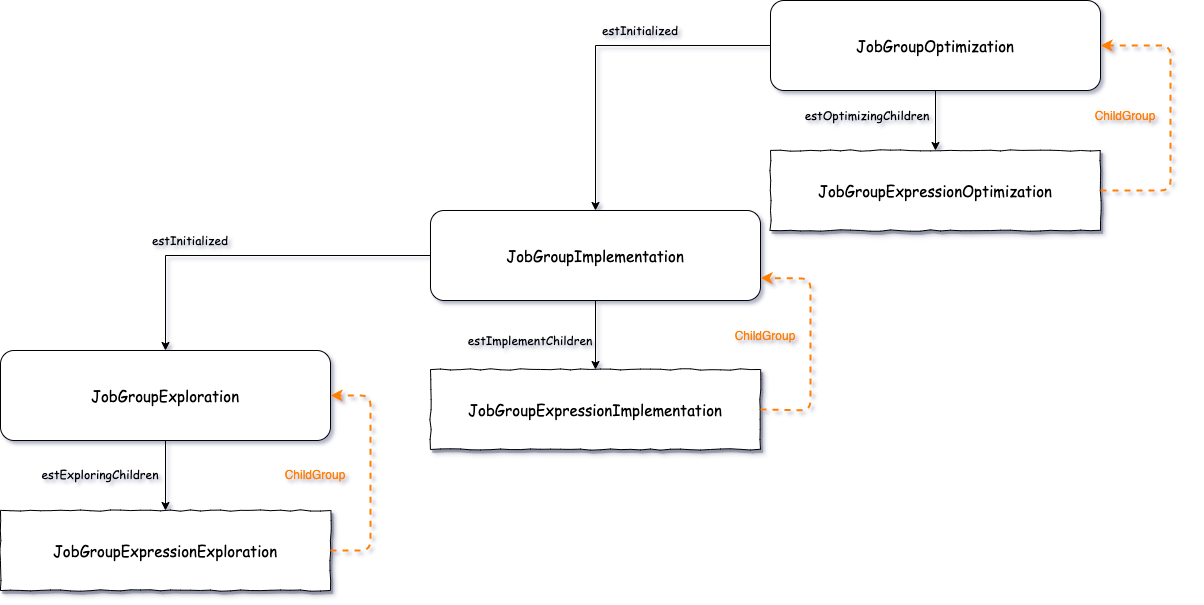 Orca把所有的优化过程都封装成了一个一个的Job,并对Job进行了多次不同的继承,来完成不同的任务。
每一个Job里都有一个状态机,会根据当前的状态机的状态,选择下一步的操作。
最早是从JobGroupOptimization开始
Orca把所有的优化过程都封装成了一个一个的Job,并对Job进行了多次不同的继承,来完成不同的任务。
每一个Job里都有一个状态机,会根据当前的状态机的状态,选择下一步的操作。
最早是从JobGroupOptimization开始
- JobGroupOptimization的状态是
estInitialized调用JobGroupImplementation - JobGroupImplementation的状态是
estInitialized调用JobGroupExpression - JobGroupExploration状态为
estInitialized执行了操作,之后会立即进入estExploringChildren.(图上未表示出来) - JobGroupExploration状态为
estExploringChildren - 当JobGroupExpressionExploration遇到 childGroup时, 又会有JobGroupExploration,为了更简洁的表示出来, 就画了一个虚线指向上边的JobGroupExploration。
- 在每一个Exploration或者Implementation,Optimization的过程中,最优的结果 会被保存在Memo中
- 最后只需要从Memo中提取出所有的最优的结果串起来的一个最大的Plan那就是我们的优化执行计划。 P.S 这里只是一个大概的过程,特别是Optimization的过程比这个还要更复杂,比如加入Enforcer这些,还有剪枝等这里都没有提到。这些都后续再来填坑吧