Columbia Optimzier
Columbia Optimzier是一个比较古老的Cascades Style Optimizer,我认为他的论文是把Cascades Style Optimizer描述的比较详细的。 这里粗略的讲一下Cascades优化器的工作上下文:
一般来说数据库Server接收到SQL之后,
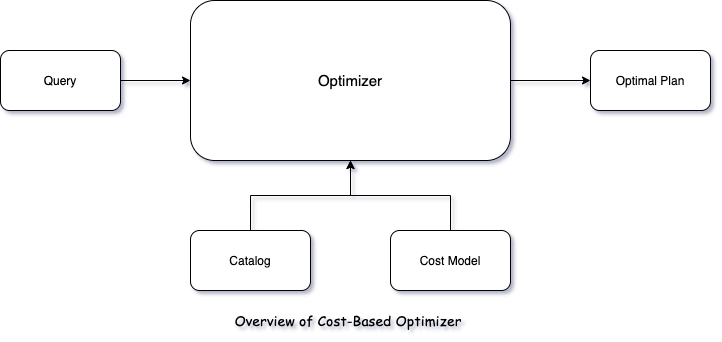
会有这么一个过程,我们的Cascades优化器是一种cost based Optmizer,它依赖于Cost Model 与Catalog/Metadata,计算出一个Cost “最小” 的Plan。 (有时候找到的并不是最小的,而是在某种搜索策略下的近似最小。
Search Space(Memo)
搜索空间?这个名词听着是不是就想到了炼丹和梯度下降?
但其实并没有关系,Cost Base Optimizer的搜索空间可以理解为在一个离散的树状结构上进行搜索。
在其它的Optimzier中一般这个叫做Memo,但是Columbia这里就叫Search Space在代码中的类是SSP。
那么Search Space该是什么样的一个东西,才能满足我们能够在它这里找到cost最小的plan呢?
Search Space最粗放的一种想法就是它是一个 Vector<Plan>
存着一个一个Plan,我们需要从其中找到cost最小的某一个Plan。
但是Plan的数字非常巨大, 用这种方式存储就非常的占用空间。
于是我们需要一个紧凑的方式能够表达出所有的Plan
下面来介绍一下Search Space的大致结构:
Search Space是由Group组成的,而Group里又包含多个Expression(Multi-Expression)
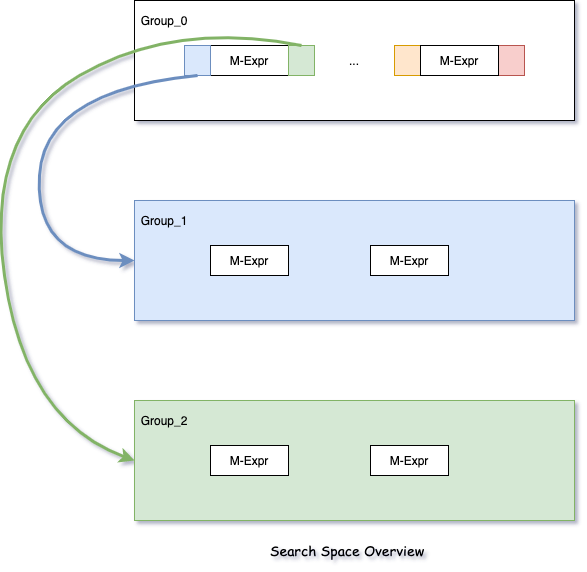
Expression: 就是一个operator<Parameter>(Input)
M-Expressions:Multi Expression把多个结果相同的Expression合写成一个Expression,使搜索空间更紧凑
Group:可以理解为多个logically equivalent的 M-Expr的集合。
假设Group_0中的第一个M-Expr是cost最小的值,而且从图上可以
看出它有两个Input:Group_1, Group_2, 把它们之间连上线,
就会发现最后输出的Plan会是一个树状结构。
Rules
Rule是在优化过程中使用到的规则,它会把Expression转换成另一个Expression,大方向来说可以分为两类:
- Transformation: logical Expreesion -> Logical Expression
- Implementation: logical Expression -> Physical Expression
Rule使用方式如下:
new_expression := Rule(old_expression)
Rule的组成主要包括三个元素:Rule 名称, pattern, substitute。
pattern:可以借助正则表达式里的pattern来理解,也就是当某个expression与这个pattern能够match上了,才能够使用这条Rule。
substitute:也可以理解为某个与pattern不一样的正则表达,即通过转换expression得到new expression,使其与substitute能够match上,这样的一条Rule的工作完成了。
Binder的内容Rules何时被调用呢?会在某一个task里调用。
Tasks
所有的优化到最后都细分成了一个一个的Task。Columbia里Task是放在某个栈上(这里存在改进空间,比如改成一个树,就可以很方便的提高并行),
直到某个Task的子Task都结束了,当前Task才会执行。总的过程:

从代码上可以看出来,过程中是把optimize top group作为一个入口,其它的task由它的perform过程来调用。
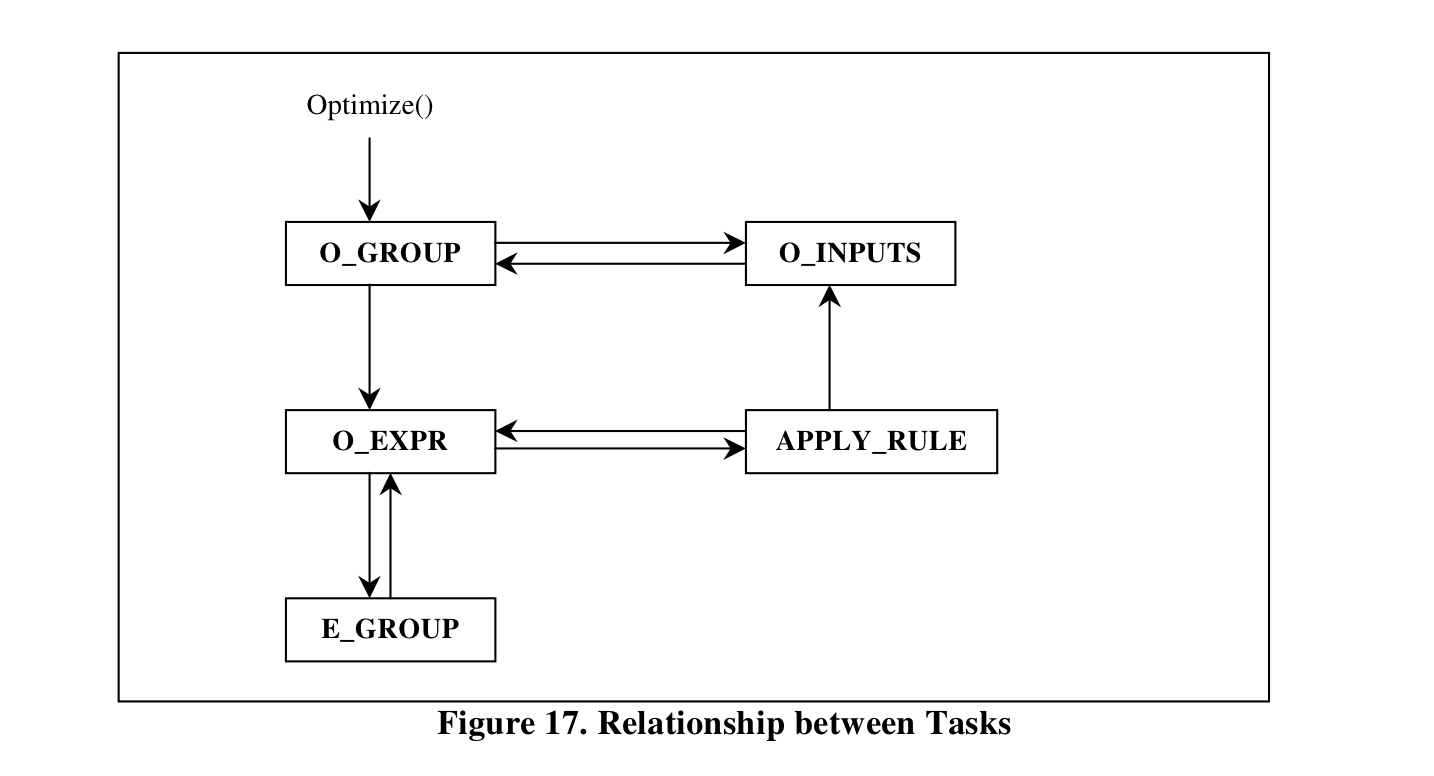 Task大致可以分为一下几类:
Task大致可以分为一下几类:
- O_GROUP: Optimize Group
- E_GROUP: Expand(Explore) the group
- O_EXPR: Optmize a multi-expression
- O_INPUTS: Optimize inputs and derive cost of an expression
- APPLY_RULE: Apply a Rule to a Multi-Expression
比起Cascades里的6种task,这里把E_EXPR与O_EXPR都整合在O_EXPR里。
O_GROUP
 先检查了一下当前Group的理论下界,与Context里的上界,看是否可以进行剪枝操作。
然后再检查当前Group是否已经优化过了。最后才是对Group里的M-EXPR进行优化。这里需要注意的是,
由于Columbia的调度器用的是一个栈的结构,Last IN FIRST OUT,
所以这里是会先对physical expr先优化,再优化logical M-expr,
这么做的好处是优化physical的过程中,可能就找到了winner,后边的logical expr就可以跳过了。
先检查了一下当前Group的理论下界,与Context里的上界,看是否可以进行剪枝操作。
然后再检查当前Group是否已经优化过了。最后才是对Group里的M-EXPR进行优化。这里需要注意的是,
由于Columbia的调度器用的是一个栈的结构,Last IN FIRST OUT,
所以这里是会先对physical expr先优化,再优化logical M-expr,
这么做的好处是优化physical的过程中,可能就找到了winner,后边的logical expr就可以跳过了。
E_GROUP

先检查当前Group是否explored,然后对group中的每一个logical expression调用O_EXPR tasks( 注意参数是exploring也就是cascades那篇文章中的E_EXPR ) 最后把这个Group标志为explored,防止多次explore。
O_EXPR

对每一个m-expr,筛选可以被激活的rule。 包括以下三种情况,rule是否已经被用过了;对于exploring那么就跳过implementation rule; 检查rule与m-expr是否匹配,以及rule的promise为正;
然后按照promise由大到小排序, 最后按照上述顺序,对rule生成一个APPLY_RULE任务,并且对于当前m-expr的inputs调用E-Group任务。
APPLY_RULE
 先是检查一下rule是否已经被这个m-expr使用过了,
遍历所有的binding,检查 老的expression是否符合条件,
然后生成新的m-expr,并把新m-expr加入到搜索空间(Search Space),
如果新的m-expr是logical的,就生成一个O_EXPR;
如果新的m-expr是physical的,就计算出它的cost。
最后标记一下,当前rule已经被这个m-expr使用过。
先是检查一下rule是否已经被这个m-expr使用过了,
遍历所有的binding,检查 老的expression是否符合条件,
然后生成新的m-expr,并把新m-expr加入到搜索空间(Search Space),
如果新的m-expr是logical的,就生成一个O_EXPR;
如果新的m-expr是physical的,就计算出它的cost。
最后标记一下,当前rule已经被这个m-expr使用过。
O_INPUTS
 这个算是比较复杂的一个过程,其中包括了一些剪枝操作,减小了搜索空间,提高了优化效率。
计算InputGroup的cost。
先计算有property要求的Group的cost
再计算没有property要求的Group的cost
并根据cost进行了一定的剪枝操作。
这个算是比较复杂的一个过程,其中包括了一些剪枝操作,减小了搜索空间,提高了优化效率。
计算InputGroup的cost。
先计算有property要求的Group的cost
再计算没有property要求的Group的cost
并根据cost进行了一定的剪枝操作。
pruning Tech
由于搜索空间十分巨大,剪枝是提高CBO效率的一个重要手段。 这里Columbia介绍两个方法:
- Global epsilon
- Lower Bound Group Pruning
Global epsilon pruning
Global epsilon pruning,是给定某个阈值,当某一个Group里已经有一个physical plan了,并且它的cost比阈值低, 就认为这个plan是optimial了,不再这个Group里再折腾了。这样虽然不一定真的最优,但是减小了搜索空间。
Lower Bound Group Pruning
给出一个Group,我们可以根据它的logical property计算出它Cost的下界值,即可能的最小值。
在优化的过程中,会有一个upper bound上界值,当这个Group的下界 〉上界值,我们认为这个Group没有值得优化的机会,
就会放弃这个Group,这个过程就是剪枝pruning。